Project IV: Drug Target Identification
Problem Statement
Drug discovery and development pipeline is resource-intensive and time-consuming, which make them a major obstacle for rapid drug development. Current challenge is to develop discovery pipelines that can identify promising drug compounds early. A reliable method that can identify the potential drug compound with respect to its successful clinical translatability is needed today.
Objectives
- Established a prototype pipeline to rank potential drug compounds for drug discovery to reduce the time and costs of drug development.
- Calculated PubChem Fingerprints using PaDEL-Descriptor.
- Built machine learning models(decision tree, random forest, gradient boosting, logistic regression, SVM, DNN, LSTM) for molecular structure analysis to predict compounds’ bioactivity toward selected targets.
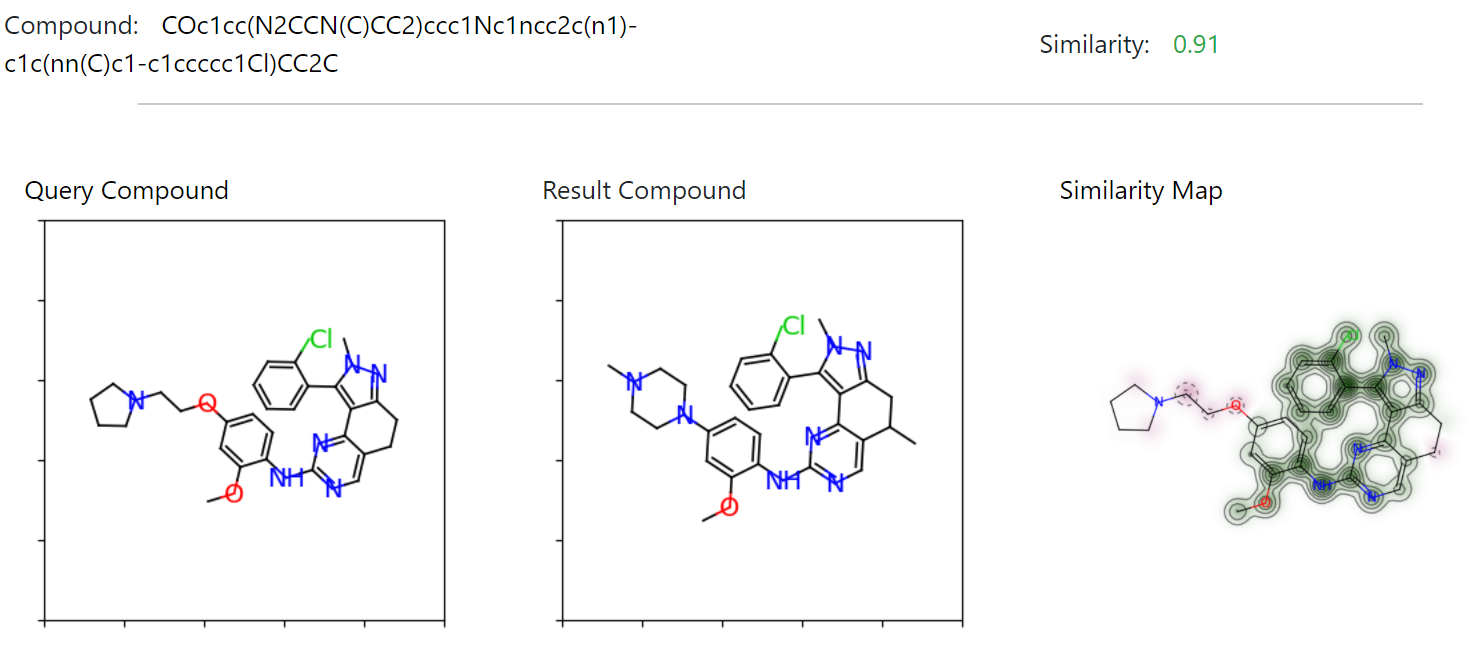
- Found active compounds with similar chemical structure (> 90% similarity) using RDKit.
- Built a client-facing API using Python Django.